从0到1使用Kubernetes系列(五):Kubernetes Scheduling
Kubernetes作为一个容器编排调度引擎,资源调度是它的最基本也是最重要的功能。当开发者部署一个应用时它运行在哪个节点?这个节点满不满足开发的运行要求?Kubernetes又是如何进行资源调度的呢?
▌通过本文可了解到以下信息:
- 资源请求及限制对pod调度的影响
- 查看调度事件events
- 了解label选择器对pod调度的影响
- 了解节点亲和性和Pod亲和性对调度的影响
- 不使用调度器,手动调度一个pod
- 了解Daemonset的角色
- 了解如何配置Kubernetes scheduler
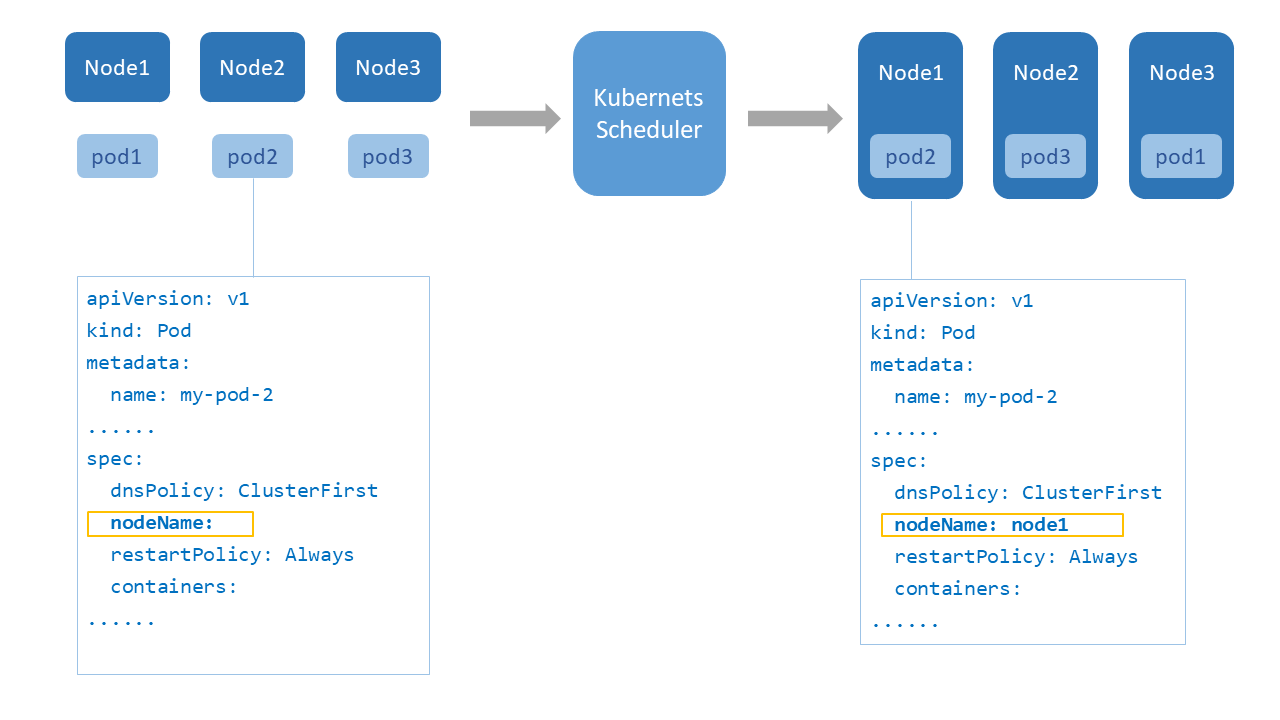
在Kubernetes中有一个kube-scheduler组件,该组件运行在master节点上,它主要负责pod的调度。Kube-scheduler监听kube-apiserver中是否有还未调度到node上的pod(即Spec.NodeName为空的Pod),再通过特定的算法为pod指定分派node运行。如果分配失败,则将该pod放置调度队列尾部以重新调度。调度主要分为几个部分:首先是预选过程,过滤不满足Pod要求的节点。然后是优选过程,对通过要求的节点进行优先级排序,最后选择优先级最高的节点分配,其中涉及到的两个关键点是过滤和优先级评定的算法。调度器使用一组规则过滤不符合要求的节点,其中包括设置了资源的request和指定了Nodename或者其他亲和性设置等等。优先级评定将过滤得到的节点列表进行打分,调度器考虑一些整体的优化策略,比如将Deployment控制的多个副本集分配到不同节点上等。
资源请求及限制对pod调度的影响
在部署应用时,开发者会考虑到使这个应用运行起来需要多少的内存和CPU资源的使用量,这样才能判断应将他运行在哪个节点上。在部署文件resource属性中添加requests字段用于说明运行该容器所需的最少资源,当调度器开始调度该Pod时,调度程序确保对于每种资源类型,计划容器的资源请求总和必须小于节点的容量才能分配该节点运行Pod,resource属性中添加limits字段用于限制容器运行时所获得的最大资源。如果该容器超出其内存限制,则可能被终止。 如果该容器可以重新启动,kubelet会将它重新启动。如果调度器找不到合适的节点运行Pod时,就会产生调度失败事件,调度器会将Pod放置调度队列以循环调度,直到调度完成。
在下面例子中,运行一个nginx Pod,资源请求了256Mi的内存和100m的CPU,调度器将判断哪个节点还剩余这么多的资源,寻找到了之后就会将这个Pod调度上去。同时也设置了512Mi的内存和300m的CPU的使用限制,如果该Pod运行之后超出了这一限制就将被重启甚至被驱逐。
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- name: nginx
image: nginx
resources:
requests:
memory: "256Mi"
cpu: "100m"
limits:
memory: "512Mi"
cpu: "300m"
参考文档:
Assign CPU Resources to Containers and Pods
Assign Memory Resources to Containers and Pods
查看调度事件events
在部署应用后,可以使用 kubectl describe 命令进行查看Pod的调度事件,下面是一个coredns被成功调度到node3运行的事件记录。
$ kubectl describe po coredns-5679d9cd77-d6jp6 -n kube-system
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 29s default-scheduler Successfully assigned kube-system/coredns-5679d9cd77-d6jp6 to node3
Normal Pulled 28s kubelet, node3 Container image "grc.io/kubernetes/coredns:1.2.2" already present on machine
Normal Created 28s kubelet, node3 Created container
Normal Started 28s kubelet, node3 Started container
下面是一个coredns被调度失败的事件记录,根据记录显示不可调度的原因是没有节点满足该Pod的内存请求。
$ kubectl describe po coredns-8447874846-5hpmz -n kube-system
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 22s (x3 over 24s) default-scheduler 0/3 nodes are available: 3 Insufficient memory.
label选择器对pod调度的影响
例如开发者需要部署一个ES集群,由于ES对磁盘有较高的要求,而集群中只有一部分节点有SSD磁盘,那么就需要将标记一下带有SSD磁盘的节点即给这些节点打上Lable,让ES的pod只能运行在带这些标记的节点上。
Lable是附着在K8S对象(如Pod、Service等)上的键值对。它可以在创建对象的时候指定,也可以在对象创建后随时指定。Kubernetes最终将对labels最终索引和反向索引用来优化查询和watch,在UI和命令行中会对它们排序。通俗的说,就是为K8S对象打上各种标签,方便选择和调度。
查看节点信息。
$ kubectl get nodes NAME STATUS ROLES AGE VERSION node1 Ready etcd,master 128m v1.12.4 node2 Ready etcd,lb,master 126m v1.12.4 node3 Ready etcd,lb,worker 126m v1.12.4选择出有SSD磁盘的节点,并给这个节点打上标记(label)。
$ kubectl label nodes <your-node-name> disktype=ssd node/<your-node-name> labeled验证节点上是否有成功打上对应label。
$ kubectl get nodes --show-labels NAME STATUS ROLES AGE VERSION LABELS node1 Ready etcd,master 139m v1.12.4 ...disktype=ssd,kubernetes.io/hostname=node1... node2 Ready etcd,lb,master 137m v1.12.4 ...kubernetes.io/hostname=node2... node3 Ready etcd,lb,worker 137m v1.12.4 ...kubernetes.io/hostname=node3...创建一个ES的pod, 调度到有SSD磁盘标记的节点上。在pod的配置里, 要指定nodeSelector属性值为disktype:ssd。这意味着pod启动后会调度到打上了disktype=ssd标签的node上。
apiVersion: v1 kind: Pod metadata: name: es spec: containers: - name: es image: es nodeSelector: disktype: ssd验证pod启动后是否调度到指定节点上。
$ kubectl get pods -o wide NAMESPACE NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE default es-5679d9cd77-sbmcx 1/1 Running 0 134m 10.244.2.3 node1 <none>
参考文档:
- Assign Pods to Nodes
节点亲和性和Pod亲和性对调度的影响
上小节讲述的nodeSelector提供了一种非常简单的方法,可以将pod限制为具有特定标签的节点。而更为强大的表达约束类型则可以由Affinity和Anti-affinity来配置。即亲和性与反亲和性的设置。亲和性和反亲和性包括两种类型:节点(反)亲和性与Pod(反)亲和性。
Node affinity与NodeSelector很相似,它允许你根据节点上的标签限制你的pod可以在哪些节点上进行调度。目前有两种类型的节点关联,称为required During Scheduling Ignored During Execution和 preferred During Scheduling Ignored During Execution。可以将它们分别视为“硬规则”和“软规则”,前者指定了要将 pod调度到节点上必须满足的规则,而后者指定调度程序将尝试强制但不保证的首选项。名称中的“Ignored During Execution”部分意味着,类似于nodeSelector工作方式,如果节点上的标签在运行时更改,不再满足pod上的关联性规则,pod仍将继续在该节点上运行。Pod affinity强调的是同一个节点中Pod之间的亲和力。可以根据已在节点上运行的pod上的标签来约束pod可以调度哪些节点上。比如希望运行该Pod到某个已经运行了Pod标签为app=webserver的节点上,就可以使用Pod affinity来表达这一需求。
目前有两种类型Pod亲和力和反亲和力,称为required During Scheduling Ignored During Execution以及 preferred During Scheduling Ignored During Execution,其中表示“硬规则”与“软规则”的要求。类似于Node affinity,IgnoredDuringExecution部分表示如果在Pod运行期间改变了Pod标签导致亲和性不满足以上规则,则pod仍将继续在该节点上运行。无论是Selector还是Affinity,都是基于Pod或者Node的标签来表达约束类型。从而让调度器按照约束规则来调度Pod运行在合理的节点上。
节点亲和性如下所示,其中亲和性定义为:该pod只能放置在一个含有键为kubernetes.io/hostname并且值为node1或者node2标签的节点上。此外,在满足该标准的节点中,具有其键为app且值为webserver的标签的节点应该是优选的。
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: kubernetes.io/hostname
operator: In
values:
- node1
- node2
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 1
preference:
matchExpressions:
- key: app
operator: In
values:
- webserver
containers:
- name: with-node-affinity
image: k8s.gcr.io/pause:2.0
Pod反亲和性如下所示,其中反亲和性定义为:在此拓扑域(相当于以topologyKey的值进行的节点分组)中,命名空间为default下有标签键为app,标签值为redis的Pod时不在此Node上运行。
apiVersion: v1
kind: Pod
metadata:
name: with-node-affinity
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- redis
namespaces:
- default
topologyKey: kubernetes.io/hostname
containers:
- name: with-node-affinity
image: k8s.gcr.io/pause:2.0
不使用调度器, 手动调度一个pod
Scheduling过程的本质其实就是给Pod赋予nodeName属性合适的值。那么在开发者进行Pod部署时就直接指定这个值是否可行呢?答案是肯定的。如下配置,将nginx直接分配到node1上运行。
apiVersion: v1
kind: Pod
metadata:
name: nginx
spec:
containers:
- image: nginx
name: nginx
nodeName: node1
还有一种指定节点的部署方式——static pod,就像它名称一样,他是一个“静态”的Pod,它不通过apiserver,直接由kubelet进行托管。在kubelet的启动参数中–pod-manifest-path=DIR,这里的DIR就是放置static pod的编排文件的目录。把static pod的编排文件放到此目录下,kubelet就可以监听到变化,并根据编排文件创建pod。还有一个启动参数–manifest-url=URL,kubelet会从这个URL下载编排文件,并创建pod。static pod有一个特性是我们使用docker或kubectl删除static pod后, static pod还能被kubelet进程拉起。通过这种方式保证了应用的可用性。有点相当于systemd的功能, 但比systemd好的一点是, static pod的镜像信息会在apiserver中注册。 这样的话, 我们就可以统一对部署信息进行可视化管理。 此外static pod是容器, 无需拷贝二进制文件到主机上, 应用封装在镜像里也保证了环境的一致性, 无论是应用的编排文件还是应用的镜像都方便进行版本管理和分发。
在使用kubeadm部署kubernetes集群时,static pod得到了大量的应用,比如 etcd、kube-scheduler、kube-controller-manager、kube-apiserver 等都是使用 static pod的方式运行的。
使用static pod部署出来的pod名称与其他pod有很大的不同点,名称中没有“乱码”,只是简单的将pod的name属性值与它运行在的node的name属性值相连接而成。如下所示,coredns是通过Deployment部署出来的名称中就有部分“乱码”,而etcd,kube-apiserver这种Pod就是static pod。
$ kubectl get po --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-5679d9cd77-d6jp6 1/1 Running 0 6m59s
kube-system etcd-node1 1/1 Running 0 6m58s
kube-system etcd-node2 1/1 Running 0 6m58s
kube-system etcd-node3 1/1 Running 0 6m54s
kube-system kube-proxy-nxj5d 1/1 Running 0 6m52s
kube-system kube-proxy-tz264 1/1 Running 0 6m56s
kube-system kube-proxy-zxgxc 1/1 Running 0 6m57s
了解Daemonset角色
DaemonSet是一种控制器,它确保在一些或全部Node上都运行一个指定的Pod。这些Pod就相当于守护进程一样不期望被终止。当有Node加入集群时,也会为他们新增一个Pod。当有Node从集群移除时,对应的Pod也会被回收。当删除DaemonSet时将会删除它创建的所有Pod。一般情况下,Pod运行在哪个节点上是由Kubernates调度器选择的。但是在Kubernates 1.11版本之前由DaemonSet Controller创建的Pod在创建时已经确定了在哪个节点上运行(pod在创建的时候.spec.nodeName字段就指定了, 因此会被scheduler忽略),所以即使调度器没有启动DaemonSet Controller创建的Pod仍然也可以被分配node。直到Kubernates 1.11版本,DaemonSet的pod由scheduler调度才作为alpha特性引入。在上小节中kube-proxy就是以DaemonSet的方式进行运行的。
配置Kubernetes scheduler
如果需要配置一些高级的调度策略以满足我们的需要,可以修改默认调度程序的配置文件。kube-scheduler在启动的时候可以通过–policy-config-file参数来指定调度策略文件,开发者可以根据自己的需要来组装Predicates和Priority函数。选择不同的过滤函数和优先级函数。调整控制优先级函数的权重和过滤函数的顺序都会影响调度结果。
官方的Policy文件如下:
kind: Policy
apiVersion: v1
predicates:
- {name: PodFitsHostPorts}
- {name: PodFitsResources}
- {name: NoDiskConflict}
- {name: NoVolumeZoneConflict}
- {name: MatchNodeSelector}
- {name: HostName}
priorities:
- {name: LeastRequestedPriority, weight: 1}
- {name: BalancedResourceAllocation, weight: 1}
- {name: ServiceSpreadingPriority, weight: 1}
- {name: EqualPriority, weight: 1}
其中predicates区域是调度的预选阶段所需要的过滤算法。priorities区域是优选阶段的评分算法。
总结
再来回顾一下调度的主要构成部分:首先是预选过程,过滤掉不满足Pod要求的节点,然后是优选过程,对通过要求的节点进行优先级排序,最后选择优先级最高的节点进行分配。当调度器不工作时或有临时需求可以手动指定nodeName属性的值,让其不通过调度器进行调度直接运行在指定的节点上。
关于猪齿鱼
Choerodon 猪齿鱼是一个全场景效能平台,基于 Kubernetes 的容器编排和管理能力,整合 DevOps 工具链、微服务和移动应用框架,来帮助企业实现敏捷化的应用交付和自动化的运营管理的平台,同时提供 IoT、支付、数据、智能洞察、企业应用市场等业务组件,致力帮助企业聚焦于业务,加速数字化转型。
大家也可以通过以下社区途径了解猪齿鱼的最新动态、产品特性,以及参与社区贡献:
作者:钟梓凌&黄显东
出处:Choerodon
欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。